今天我们介绍的这篇论文PromptFuzz: Prompt Fuzzing for Fuzz Driver Generation来自CCS 2024,投稿者(也是论文的第一作者)吕云龙曾在G.O.S.S.I.P期间实习时就以一作身份发表IEEE S&P 2022论文(Goshawk)。他在毕业并加入Tencent Security Big Data Lab之后,又为我们带来了新的研究成果PromptFuzz,这是继自动化生成Fuzz Driver的Hopper【[G.O.S.S.I.P 阅读推荐 2023-11-08 Fuzz Anything】之后,探索智能化生成Fuzz Driver的又一项工作,让我们来看看:

Background
模糊测试(Fuzzing)技术是提高软件安全性和稳定性的关键技术之一。不同于对输入字节流进行处理的命令行程序的模糊模式,代码库模糊测试对多个应用程序接口(API 函数)进行处理,并且需要更加严格的输入来遵从API严格的输入限制。模糊测试驱动(Fuzz Driver)通常由开发者来编写,对代码库接口进行调用和输入字节流的转换,来实现对代码库的模糊测试。
在开源社区成千上万个开发者的贡献之下,已有技术如OSS-Fuzz在众多项目中已成功发现并修复了大量漏洞。但对于代码库而言,如何自动生成高质量的模糊测试驱动(Fuzz Driver)仍然是一个挑战,它需要自动化方法对目标代码库有很深的理解才行。
例如下图为视频编解码库Libvpx的一个Fuzz Driver,为了能测试Libvpx的解码器,它需要做以下事情:
正确地调用解码API函数,来模拟视频解码过程。
从输入的随机字节流中为每个API函数构建正确的参数。
尽可能多地使API函数执行更多的代码。如第25–27行,通过一个循环实现对输入字节流的最大化吞吐。

为了生成一个高质量的Fuzz Driver,遵循目标代码库的使用约束并且彻底地测试每个API函数是必要的。现有的方法缺少对代码库很深的理解,而本文介绍的PromptFuzz则是利用大模型改进了这一流程,来更有效地生成模糊测试驱动深入探索API函数。
Workflow
PromptFuzz以代码覆盖率为引导,通过不断地对大型语言模型(LLM)的提示(prompt)进行优化来生成高质量的模糊驱动程序,以此实现对代码库漏洞的有效检测。与那些通过变异输入字节以触及更深层程序代码的灰盒模糊方案不同,PromptFuzz通过变异LLM prompts来生成能够更广泛利用代码库API的程序,来达到对代码库深层次逻辑的覆盖。一开始,它会随机地从代码库中抽选API函数组成一个LLM prompt,随后会基于覆盖率来对其进行持续的变异,直到在此代码库上达到收敛状态。由这些prompts生成的代码经过验证后会被用来进行模糊测试,发现代码库中的安全问题。
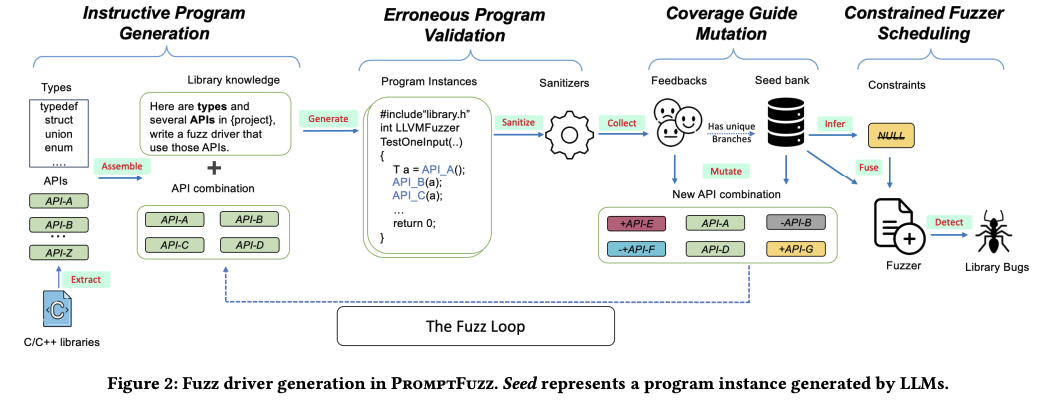
它的工作流程如图2所示:
从C/C++库的头文件中抽取API函数签名和类型定义,并利用这些信息构建prompts,指导大型语言模型(LLM)生成调用这些函数的程序。
执行所生成的程序,根据它们的实际运行行为来验证这些程序的正确性,并剔除错误的实例。同时,它会在执行过程中收集代码覆盖率信息。
将通过验证的程序存储在一个种子库中并利用这些程序的代码覆盖情况作为反馈,指导对先前prompts的变异过程,使其更倾向于探索那些能够触达新代码路径的API函数。
这一迭代过程会持续进行,直至发现没有新的代码路径可探索,或是查询资源(如时间、计算力等)耗尽为止。这样的策略有助于高效地扩大测试范围,挖掘潜在的边缘情况和漏洞。
-
最终,PromptFuzz从种子程序中推断出施加于库API函数的约束条件。根据约束条件,它将API调用中的常量参数转换为能接受随机输入的变量,来实现对API参数的测试。所有经过转换后的种子程序会被融合进一个Fuzz Driver中,并独立地根据随机输入进行调度。
Instructive Program Generation
因为现有的很多大模型,如ChatGPT和GPT4,都是用了基于强化学习的微调(RLHF)技术来进行训练,使得这些模型能够一定程度上跟随用户输入的指令生成所想要的代码,这就一定程度上允许我们来通过改变prompt中的内容来影响产生什么样的代码。尽管大模型并不总是严格遵循指令来生成所需的程序,但通过这些指令生成的代码会有助于探索代码库的有效使用方式。
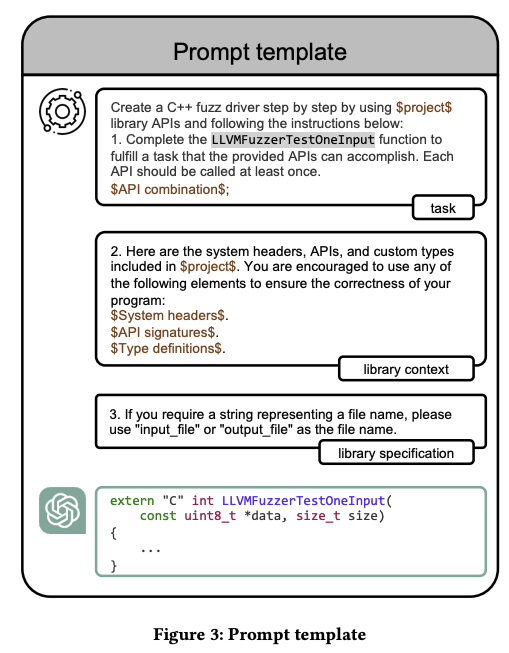
基于以上见解,我们并没有采取很复杂的prompt工程,而是简单地构造了如下的prompt模版,来引导大模型生成测试程序。此模版分为三部分:task、library context 和library specifiction。其中task为最重要的部分,它告诉了大模型来主要围绕所提供的几个API函数来进行调用程序生成。library context和library specifiction则是为了提供足够的信息,来降低大模型“幻觉”的影响或者适配于特定的代码库逻辑。
Erroneous Program Validation
受限于训练数据偏差以及LLMs在代码合成能力上的不完美,LLMs生成的代码可能含有错误。而一个理想的模糊测试程序至少应该是其自身代码无误的,以便运行时的所有错误都能归因于目标调用的库代码。鉴于LLMs无法持续生成无误的程序,我们开发了此技术来识别由LLMs生成的错误程序。
识别语法错误较为直接,而识别语义错误则更为复杂。在用于测试库的程序中,语义错误既包括库使用的错误,也包括一般的编程错误,如内存错误和控制流错误。精确地识别这些错误极具挑战性,因为它需要对库有深入的理解,并且可能需要执行复杂的静态和动态分析,这些分析通常耗时较长、资源密集且难以泛化。
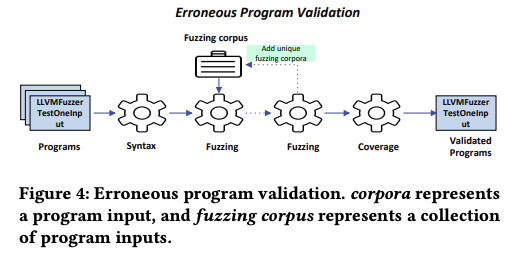
不幸的是,现在没有一种开箱即用的方案,来准确判定大模型输出的代码是否正确。为此,我们设计了一个错误程序验证方法,如图4所示:
首先,它依据C/C++编译器的检查结果,移除含有语法错误的程序。
接着,将剩余程序编译为可执行文件,并集成多种运行时 sanitizer(如 AddressSanitizer 等),用以捕获及分析偏离预期行为模式的情况。
它使用提供的语料库对这些程序进行模糊测试,并移除任何被 sanitizer 检测到偏差的程序。在模糊测试过程中,PromptFuzz 将触发独特行为的输入添加到语料库中,以此扩展语料库,以便进行更全面的基于运行时的验证。模糊测试之后,它计算各程序达到的代码覆盖情况,并移除未达到代码覆盖率标准的程序,这表明了对库API函数的充分运用与测试覆盖。
基于覆盖率的验证,是使用静态分析计算出critical paths,来验证目标API是否被执行过,详情见论文。
Coverage Guide Muation
为了创建后续轮次的LLM prompts,PromptFuzz会变异前一轮prompt中的API组合。尽管LLMs能够通过组合不同的API函数来生成程序,但如果仅随机组合这些API会使得变异效率低下。为了能够更有效地生成有价值的LLM prompts,PromptFuzz基于代码覆盖率设计了基于API级别的能量调度策略(Power Schedule)和prompt级别的变异策略(Mutation Strategy)。
Power Schedule的设计启发于AFLfast,它会根据每个API的覆盖率情况来决定每个API被选入LLM prompt的概率,覆盖率越高(意味着此API测试越充分)则其能量越低。
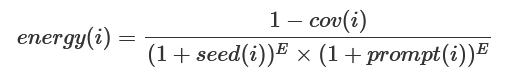
如果仅根据每个API的能量来组成API combination放入LLM prompt中进行程序生成,这会导致用于测试程序生成的API之间毫无关联。而忽视API之间的依赖关系,会导致LLM很难来根据目标API combiantion生成复杂的测试用例,来探索具有复杂API间约束的场景。
为此,PromptFuzz在prompt层次针对性的根据API combination设计了变异操作:
Insertion(C, A):将API A插入到combination C中。
Replacement(C, A, B):在combination C中替换API A与 API B。
CrossOver(C, S):将combination C与combination S做交叉。
并根据覆盖率,计算出每个种子程序的质量,来侧面推演出生成每个种子程序对应的API combination的质量,根据以下规则来对用于prompt构建的API combination进行变异:

Constrained Fuzzer Scheduling
在前面针对prompt的fuzzing阶段达到收敛状态后,因为LLM倾向于为API函数生成默认的参数,我们需要将LLM 生成的程序做适当的转换,以便来进行更加充分的模糊测试。如下图所示,我们需要将常量参数转化为可变参数:
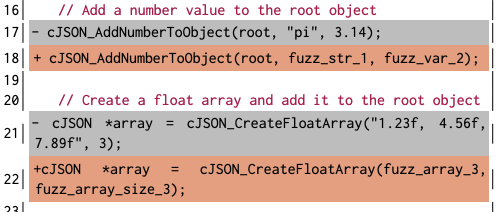
但又因为很多API函数对参数施加了很多约束,我们需要推断出这些参数约束,以此来保证这样的参数转换不会造成违反约束。在文章中,我们基于大模型生成的代码主要使用静态方法来对如下的约束进行识别:
ArrayLength
ArrayIndex
FileName
FormatString
AllocSize
FileDesc
这一部分主要是一些工程化的工作,感兴趣可以去阅读我们的原文。
Evaluation
我们将PromptFuzz应用在了14个开源库上来生成模糊驱动程序并检测其中的错误。这些实验的结果总结在表1中,在其中提供了关于被测试库、所生成模糊驱动程序、分支覆盖率以及错误检测结果的统计数据。总的来说,PromptFuzz在总共204小时内成功为这14个库生成了3785个种子程序,向LLMs查询的总成本为63.14美元(平均每个代码库成本仅为4.15美元)。并且PromptFuzz生成的模糊驱动程序在被测试库上达到了40.07%的分支覆盖率,比OSS-Fuzz高出1.61倍,比Hopper高出1.63倍,并在24小时的实验期间发现了30个之前未知的错误。所有发现的错误都已报告给相应的社区。
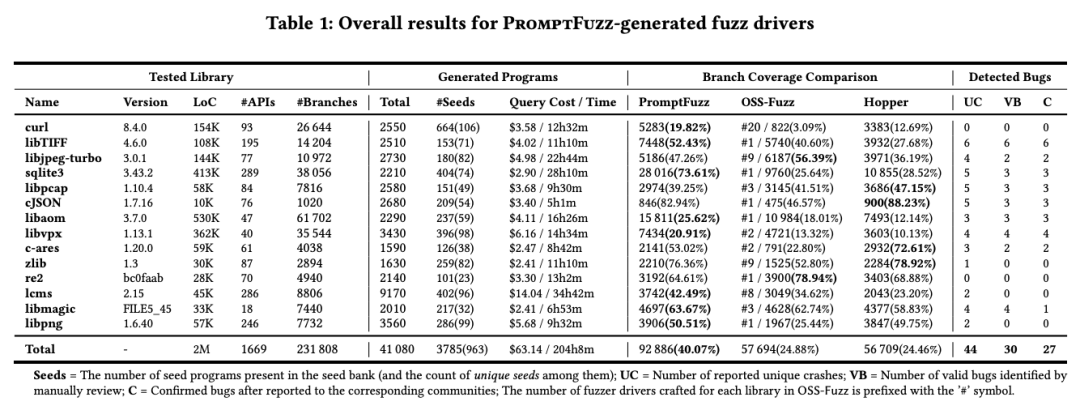
我们发现,在检测Bug阶段产生的14个无效警告中,有8个是由于对库API调用返回的空指针进行解引用而产生的。对API常量参数的转换显著增强了模糊驱动程序的错误发现能力,但同时也增加了库API调用进入错误状态并返回空指针的可能性。如果随后的库API调用在没有实现对这些空指针参数处理的情况下访问这些空指针,就可能会发生非实质性崩溃。但需要注意的是,我们不把这些崩溃视为PromptFuzz错误检测中的假阳性结果。相反,它们是源于库API函数未能妥善处理传入的空指针的健壮性问题。排除掉因库API健壮性问题而报告的8个警告后,只有6个崩溃被认定为PromptFuzz错误检测中的假阳性。
因此,我们认为PromptFuzz在错误检测的准确性上达到了86.36%(38/44),这里38代表真正识别出的错误数量,而44是总识别出的潜在错误数量(包括真正的错误和假阳性的总和)减去因库API自身健壮性问题引发的警告数量。这一结果显示了PromptFuzz在提高模糊测试效率和精确度方面的有效性和潜力。
Future
目前此项目已经进行了开源,但只在少数(14个)的代码库上进行了应用部署,已经发现了不少的安全bug。我们欢迎大家提PR来让PromptFuzz对更多的代码库进行支持(只需要少量的工作),想挖掘CVE的朋友一定要试试哦。
论文地址:https://arxiv.org/pdf/2312.17677
代码仓库:https://github.com/PromptFuzz/PromptFuzz